
The Agentic BioML Challenge
We're going to make 🤖 do science.

Is the next big leap in biotech going to be automated, AI-driven R&D? Over the coming months I’ll be stress-testing this idea by building AI agents that can solve a diverse range of challenging biomedical machine learning problems autonomously. If you want to join in, DM me and let’s find a way to collaborate.
Introduction: Autonomous Biotech
Imagine walking into the lab to discover that overnight, your AI‑piloted robotic research assistant completed a dozen new experiments, analyzed the results, and drafted followup experiments — all without you lifting a pipette. Now picture hundreds of similar labs worldwide, running 24/7, sharing their findings, and collectively building a rich web of biomedical knowledge. Until recently this vision of the future felt speculative; as of May 2025 it’s starting to look inevitable.
Evidence is accumulating that the era of agentic science is on the horizon. Here are some recent highlights:
🦠 Agents design nanobodies that fight COVID (Zou Lab, 2024)
🧬 SpatialAgent for autonomous spatial omics (Regev Lab, 2025)
📜 AI Scientist v2 wrote a workshop paper accepted at ICLR 2025 (Ha Lab, 2025)
🧠 DeepThought similar to human experts in drug hit ID tasks (Deep Origin, 2025)
Recent industry efforts at Insilico Medicine, FutureHouse, and Science Machine are pointing the same way.
Despite these advancements, there are only a handful of groups working on agents in the biomedical field today. And the agents that have been developed thus far typically depend on rigid, hand-tuned prompts. We need more scientists building flexible agentic systems that can serve as turn-key solutions for a wide range of challenges in biotech R&D. That’s the motivation behind this challenge series.
The Challenge Series
These challenges will test our ability to automate biomedical machine learning (BioML) with LLM-based agents. They were selected to test the breadth and depth of agent capabilities. I’m also open to additional suggestions for challenges (DM me).
Check out the GitHub: AIxBioML/AgBioML-Challenge.
RULES:
The agent system must be launched from a single command, yielding a solution to the challenge.
Evaluations must only use data that agents never had access to (typically held-out samples, cohorts, studies, etc).
Evaluation code written by humans must not augment or alter the agent solution when evaluating it.
There must be no task-specific code or system prompts baked into the agent system.
Marking a challenge as “complete” requires submitting a tarball with task prompts, agentic outputs (figures, tables, etc), chat traces, evaluation code/outputs, and the version of the challenge repo that met the “win” condition. The tarball will be released publicly and described in an accompanying Substack post.
See notes / clarifications at end*.
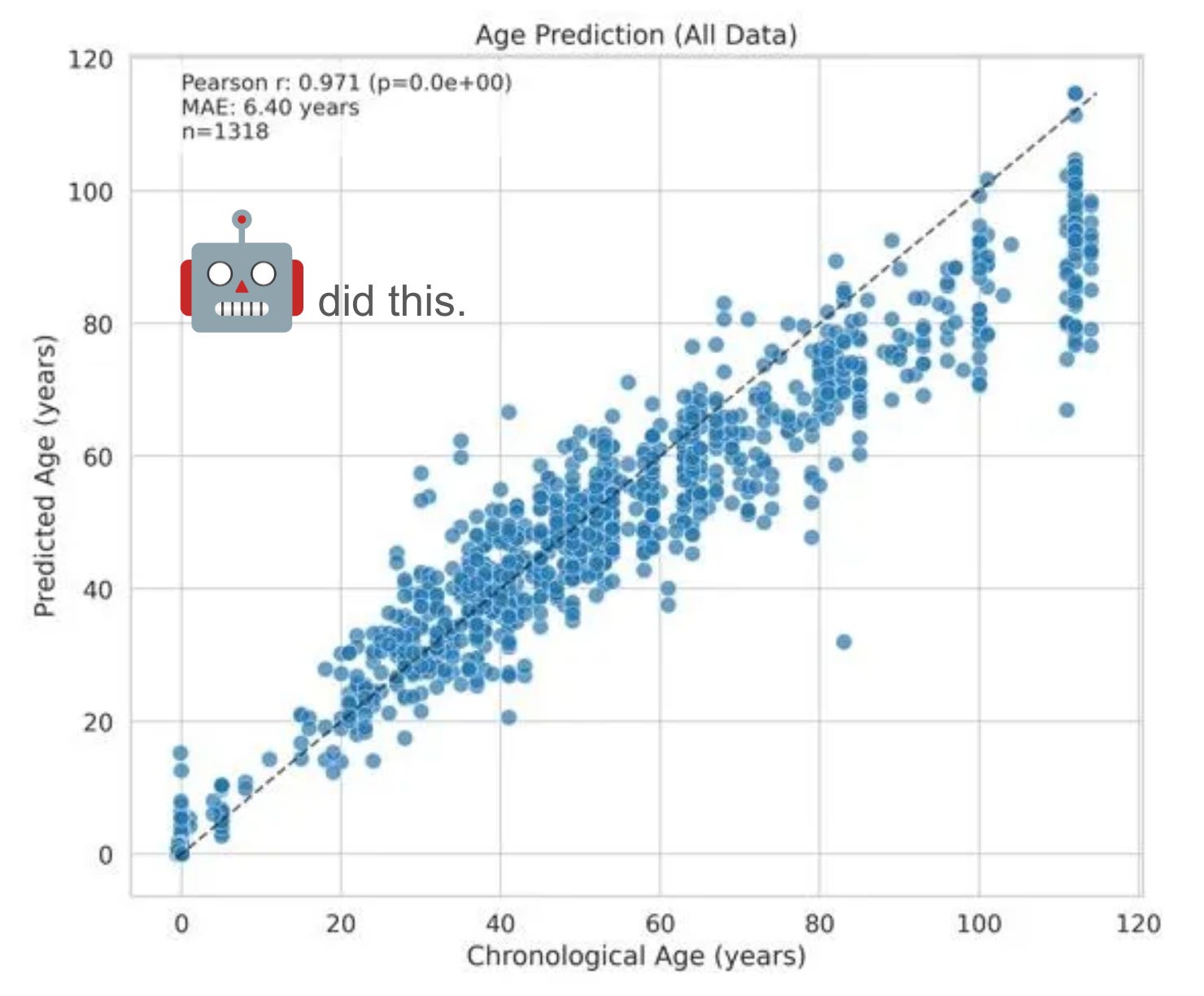
Challenge 1: Basic Epigenetic clock
Goal: Age-predictor on the AltumAge [Camillo 2022] methylation compendium.
Win: > 0.94 Pearson correlation between true / predicted age & < 8 years MAE.
Challenge 2: RSNA Screening Mammography Breast-Cancer Detection
Goal: Identify breast cancer from screening mammograms (Kaggle Link).
Win: Score within the top 25% of the leaderboard.
Challenge 3: Therapeutics Data Commons ADMET benchmark
Goal: predict ADMET properties of drugs given a SMILES string. (ADMET Benchmarking Group).
Win: Score within the top 20% of at least one leaderboard in each category of ADMET.
Challenge 4: The CellMap Challenge (2025)
Goal: Segmentation of electron microscopy images of tissues into cells, organelles, and subcellular structures (The CellMap challenge).
Win: Score within the top 15% of the overall leaderboard.
Challenge 5: DREAM Target 2035 Challenge (2025)
Goal: Given a dataset of molecules that are labeled as having activity against WDR91 or not — phase I: take a new dataset of unlabeled molecules and predict which ones are likely to be active. If a team scores within the top 25 participants, they are invited to phase II in which they will predict and test novel small molecule hits for activity against WDR91. (DREAM Target 2035 Challenge)
Win: make it to phase II.
This one has a very tight timeline (first submission by May 28th), so we might not attempt this year and instead do the DREAM Olfactory Mixtures Prediction Challenge.
Challenge 6: The Biomarkers of Aging Challenge (2025)
This challenge also hasn’t launched yet, but it will involve using DNA methylation and proteomics data to predict morbidity (disease status) in patients.
Win: Win the competition outright.
Let the games begin
If successful, we should be able to type `run_agents.py --task=<task_description>` and watch a swarm of agents crack even some of the toughest BioML problems.
🚀 Have ideas, feedback, or want to get involved? Send me a DM and let’s chat.
*Some clarifications for the rules:
There will be scaffolding and guidelines written to help agents accomplish tasks — these will be incorporated into the task prompts agents receive. Scaffolding in system prompts we be used to add guardrails to prevent undesirable agent behaviours, like infinite loops or misuse of tools. Task prompts can be tuned multiple times.
There will be options to configure which tools to provide agents with. These tools might be specific to a given task (e.g., functions to use RDKit might be provided for manipulating molecule data).
Other aspects of how the agent teams function may also be configurable, such as the number of iterations for particular subteams.
Also, agents can be given the ability to prompt a human to answer a question or perform an action on their behalf (e.g., downloading a dataset they cannot programmatically access or clarifying a problem statement). In these cases, the human cannot provide any feedback or guidance except in directly answering the agent query.
Agents can attempt a task multiple times, using findings from previous attempts as part of a new attempt (e.g., in the form of lab notebooks).
Check this out from Future House: https://www.linkedin.com/posts/samuel-g-rodriques-080a9b22_introducing-finch-a-new-agent-that-fully-activity-7325538421450424322-cxWh?utm_source=share&utm_medium=member_desktop&rcm=ACoAABKPvagB45CyVPw9bt_DBqu8u0EFpPYmw9s